技术美术百人计划学习笔记(图形3.4 延迟渲染原理介绍)

延迟渲染原理介绍
渲染路径 Rendering Path
渲染路径是决定光照的实现方式,简而言之就是当前渲染目标使用光照的流程
渲染方式
-
前向渲染(Forward Rendering)

-
延迟渲染(Deferred Rendering)

前向渲染
在渲染每一帧时,每个顶点/片元都要执行一次片元着色器代码,这时需要将所有的光照信息都传递到片元着色器中。虽然大部分情况下的光源都趋向于小型化,而其照亮的区域也不大,但即便是光源离这个像素所对应的世界空间中的位置很远,但计算光照时,还是会把所有的光源都考虑进去,会造成极大的浪费
例如,物体受n个光源影响,那么在每一个片元执行着色器代码时,都必须吧这n个光源都传递进着色器中执行光照计算
For Each light: |
延迟渲染
延迟渲染概述
主要解决大量光照渲染的方案
延迟渲染的实质,是先不要做迭代三角形做光照计算,而是先找出来你能看到的所有像素,再去迭代光照。直接迭代三角形的话,由于大量三角形你是看不到的,无疑是极大的浪费

上图中,前向渲染下,计算红绿两个不同距离的光照计算的开销是相同的(因为都是在世界空间或切线空间进行的光照计算,无法知道在屏幕空间上会显示多少像素),但是明显能看出来近处的绿光有效像素更多,说明红光造成的浪费更多;而对于延迟渲染来说,远处光照的计算开销是要远远小于近处的光照计算开销,因为延迟渲染是将所有的顶点信息都渲染到了一张基于屏幕的RT上,然后再进行光照计算
延迟渲染详细说明
将渲染过程拆分成两个渲染通路(pass):
- 第一个pass称为几何处理通路。首先将场景渲染一次,获取到待渲染对象的各种几何信息存储到名为G-buffer的缓冲区中,这些缓冲区将会在之后用作更复杂的光照计算。由于有深度测试,所以最终写入G-buffer中的各个数据都是离摄像机**最近的片元(一定可见的)**的几何属性,这意味着最后在G-buffer中的片元必定要进行光照计算的。
- 第二个pass称为光照处理通路。该pass会遍历所有G-buffer中的位置、颜色、法线等参数,执行一次光照计算。
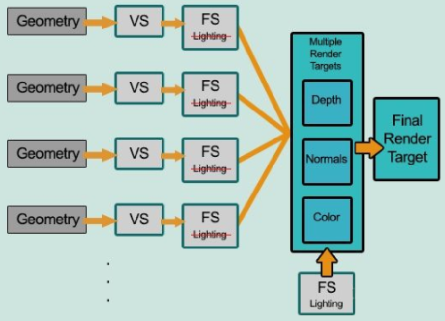
- 实际上Fragment Shader也是输出了片元颜色的,只不过没有进行光照计算
- 延迟渲染无法支持半透明物体的渲染,在延迟渲染管线下渲染半透明物体,只能是在延迟渲染处理完成之后,最后再用前向渲染的方式去渲染半透明物体
- G-Buffer中的数据都是2D的,所以最终的光照计算相当于2D的光照后处理
For each object: |
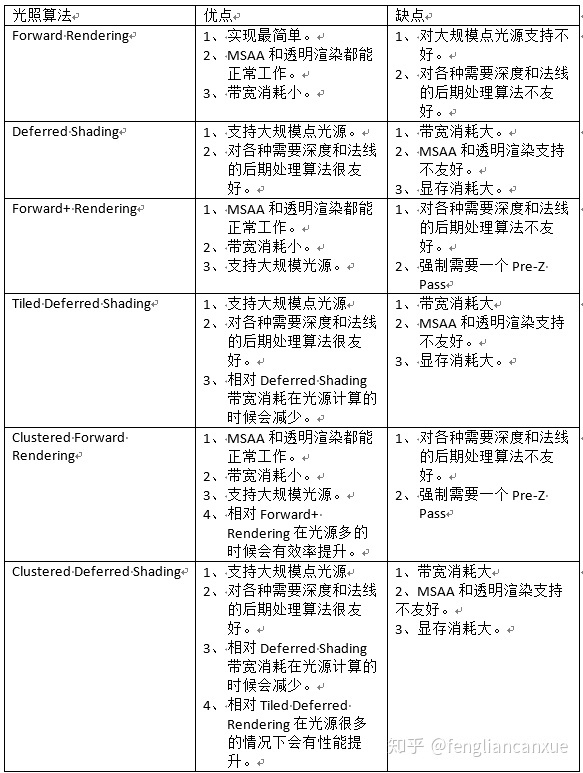
不同渲染路径的特性
后处理方式不同
如果需要深度信息来进行后处理,前向渲染就需要单独渲染出一张深度图,而延迟渲染直接从G-Buffer中拿深度图即可
着色计算不同(Shader)
由于延迟渲染光照计算统一是在LightPass中完成的,所以只能计算一个光照模型。如果需要其他的光照模型,只能切换Pass
抗锯齿方式不同
(后面细说)
不同渲染路径的优劣
前向渲染的缺点:
- 光源数量对计算复杂度影响大
- 访问深度数据时需要额外计算
前向渲染的优点:
- 支持半透明渲染
- 支持使用多个光照Pass
- 支持自定义光照计算方式
延迟渲染的缺点:
- 对MSAA支持不友好
- 透明物体渲染存在问题(深度的问题)
- 占用大量的显存带宽(每一帧都需要几张RT在显存中传输、清理)
延迟渲染的优点:
- 大量光照场景优势明显
- 只渲染可见像素,节省计算量
- 对后处理支持良好
- 用更少的shader
其他
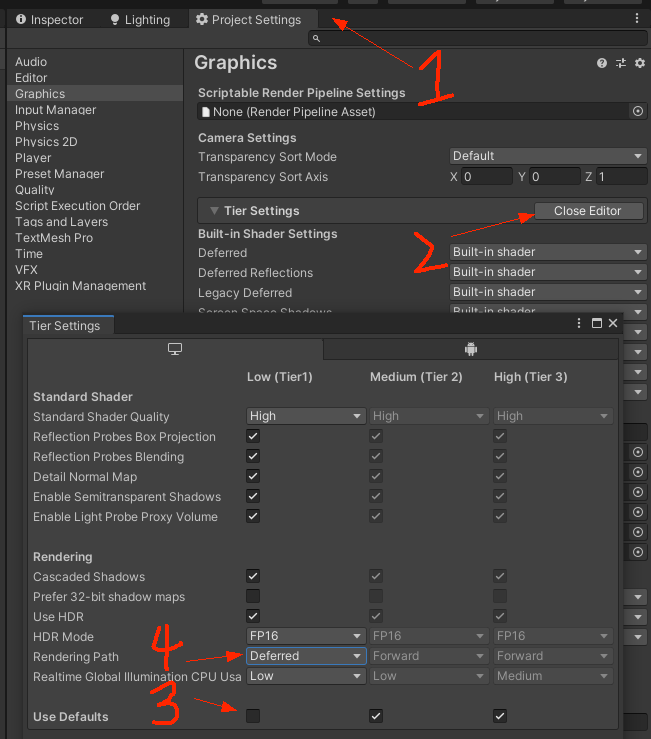
渲染路径设置

移动端优化
-
两个TBDR的优化方式
-
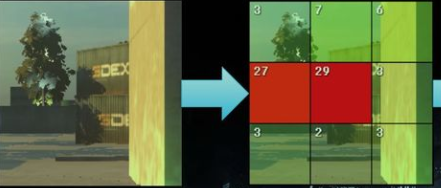
SIGGRAPH2010上提出的,通过分块来解决降低带宽内存用量
-
PowerVR基于手机GPU的TBR架构提出的,通过HSR减少overdraw(做一些可见性测试)

-
其他渲染路径
参考资料:https://zhuanlan.zhihu.com/p/54694743
延迟光照(Lighting Pre-Pass / Deferred Lighting)
减少G-Buffer占用过多开销,支持多种光照模型

Forward+(即Tiled Forward Rendering,分块前向渲染)
减少带宽,支持多光源,强制需要一个Pre-Z进行深度预计算的pass
群组渲染(Cluster Rendering)
带宽相对减少,多光源下效率提升
MSAA与延迟渲染的不兼容
MSAA在延迟渲染中的问题是:像素在进行光照计算前已经被光栅化了,MSAA需要基于sub-pixel数据进行处理,光栅化后的每个像素的sub-pixel们是一样的,处理无效,所以没有办法用精度更高的像素来进行渲染。

但是如果非要做MSAA的话,有如下参考资料:
Anti-aliased Deferred Rendering – NVIDIA
不同Path下光源shader的编写
由shader中的"LightMode"进行控制

PreZ/Zprepass

实际上就是一个深度计算,与深度图一样都是用一个pass去计算深度。PreZ与深度图的区别在于,深度图是将深度信息绘制到了一张RT上,为了记录数据并方便进行数据间的传输;而PreZ/Zprepass是硬件自动进行的,只是计算深度然后在shader中使用(做屏幕等距边缘光的时候用到了),或者透明排序的时候会涉及三段深度排序的方式,来让透明的物体深度正确。
如果在shader中要用到DepthOnlyPass获取到的深度图的话,需要勾选Depth Texture的生成——屏幕空间等距边缘光
游戏引擎中的光照算法(文中知乎链接笔记)
Forwar Render
处理多光源有限,基本算法为:
For Each Light: |
-
不可见的面会造成shading的浪费
-
Batch数量高:每个物体的每个光源就会有一个batch(1 batch/object/light)
- 如果有shadow-casting,batch会更多
-
在每个pass内有大量重复的工作
-
顶点初始化和空间变化
-
各向异性过滤
-
一般游戏引擎为了减少batch和处理光照的次数,会让每个物体受影响的光源有上限(3个或4个),并且一般是在一个shader中直接处理多个光源
Single-Pass Lighting
For Each Object: |
-
不可见的面会造成shading的浪费
-
难以管理多光源的情况
- 不同光源情况就要单独写一个shader,费时费力
-
难以和shadow合并
- 如果使用Shadow Maps:容易爆显存
Deferrd Shading
For Each Object: |
- 便于引擎管理,可以极大简化batch
- 与常见阴影技术融合度高
- 光照计算的复杂度达到“完美的$$O_{(1)}$$
- 可以处理从许许多多的小光源到一个大光源的情况

目前大多数引擎为了支持多材质,会有一个字节用于写入Material ID或者Shading Model ID(UE4)来区分不同的着色模型
Tiled Deferred Shading
(TBDR看后续的百人计划吧,感觉那篇知乎这里写得怪怪的)
在Deferred Shading的基础上按一定像素大小分块,计算每一块中光源的数量,这样我们可以对多个光源计算光照时只读取一次GBuffer信息,节省了带宽
Deferred Lighting
算法和Deferred Shading差不多,CryEngine早期版本中使用过该技术,目前基本没有引擎使用

Forward+(Tiled Forward Rendering)
最初是从AMD的论文Forward+: Bringing Deferred Lighting to the Next Level开始流行起来的
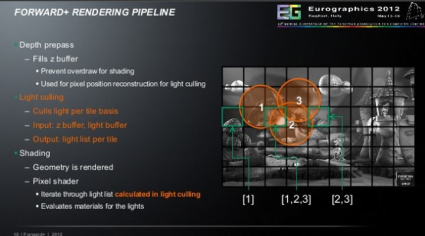
【Forward+管线总览】
-
Depth prepass
-
Fill Z Buffer
-
避免shading时的overdraw
-
用于为light culling而进行的像素位置重构
-
-
Lighting culling
-
逐个tile进行cull light
-
输入:z buffer,light buffer
-
输出:逐tile的light
-
-
Shading
-
几何信息已经被渲染了
-
Pixel Shader:
-
迭代在light culling中计算得到的light list
-
计算这些光照的材质表现
-
-
【Light Culling的细节】
使用Compute Shader来实现,细节还是后续想要去写的时候看看论文吧


Clustered Forward Rendering
在Forward+ Rendering的基础上又沿着相机深度的方向切了很多片
- Tiles被替换为了3d空间中的cluster
- 深度的分布不是线性的(猜测是信息优先级的问题,就好像屏幕空间的深度信息也不是线性的一样,用更多信息去存储高精度的近区域的深度,用更少信息去存远区域的深度)
- 比起forward+来说,逐个cluster有更少的光照
- 但是cluster的数量大于tiles的数量

【Clusters的形成(Fill Clusters)】
-
由异步的compute shader来fill clusters
-
每个cluster都被所有light进行测试
-
3个pass
-
两个等级的层级
-
18x10x32
-
36x20x64
-
【Clustering与深度】

Clustered Deferred Rendering
是延迟渲染的管线,只不过用了和forward passes一样的光照解决方案

总结
整体上我只是做了一个了解,并且纸上得来终觉浅,等之后去细实现的时候,再去好好读一读论文,实际落地并做出笔记。渲染管线的发展总结就借用文中大佬的总结来概述一下:最开始只有传统的Forward Rendering,为了解决多光源的问题,引入了Deferred Rendering,带来了很多好处,包括各种后期效果。但是带宽是个问题,于是出现了Forward Plus(Tiled) Rendering解决带宽问题,也就有了Tiled Deferred Shading,但是还可以进一步优化,那就是在Tile的基础上再切片,于是就有了Clustered Forward Rendering和Clustered Deferred Rendering
整个技术都是在基于需求进行的推进,学习亦然。