介绍
展示视频:【【仿原神渲染/MMD】我推的芭芭拉】https://www.bilibili.com/video/BV1F841167nb
十分喜欢赛璐璐风格的卡通渲染,正好开始那段时间时间在学习HLSL,心想不如基于一个实际落地的效果去边学边练,于是就开启了一段美妙(并且经常痛苦)的学习旅程!
最终的效果差强人意,但也是很好地标明了一个起点,持续改进中!
像视频简介里面说的那样,这一段时间为了在已有资源的基础上做好卡通渲染,还简单学了Maya的Python,从MEL到OpenMaya都接触了一点,最后写出了一个用于计算并存储平滑法线信息的小工具。为了在URP里写后处理,去学了URP的RenderFeature,接触了一点点SRP的知识。不过这些学习大多都是基于想要实现的效果去学的,后续还要花一些时间去整理和部分地深入,我也打算一边总结一边写一些分享文章。在这篇文章里,我就简单聊一下我是如何使用手上的资源实现目前渲染效果,关于一些技术他们更深的底层原理以及我对他们运用方式的思考,不久后我也会写出来的。毕竟,卡通渲染无法一概而论,其关注的是最后的效果,对于一个优秀卡通渲染的研究,一定要深入到每一个技术细节存在的前因后果,这样才能一步步做出更好的卡渲。
总览
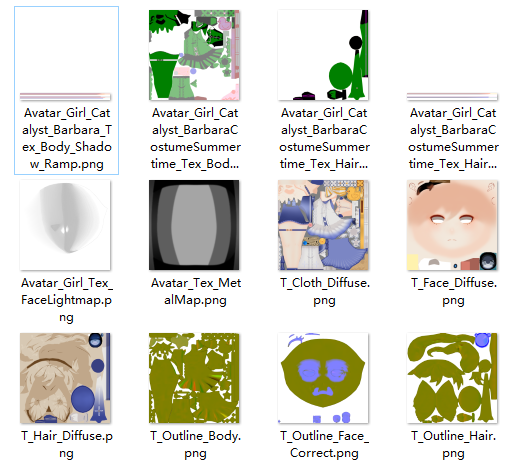
贴图资源简述
用到的贴图资源如上所示,有basecolor贴图、lightmap贴图、ramp图、matcap贴图和自制的用于存储平滑法线和描边区域信息的outline贴图,简单介绍一下各个贴图的用法
lightmap - ilmTexture
存储一些控制光照的参数信息
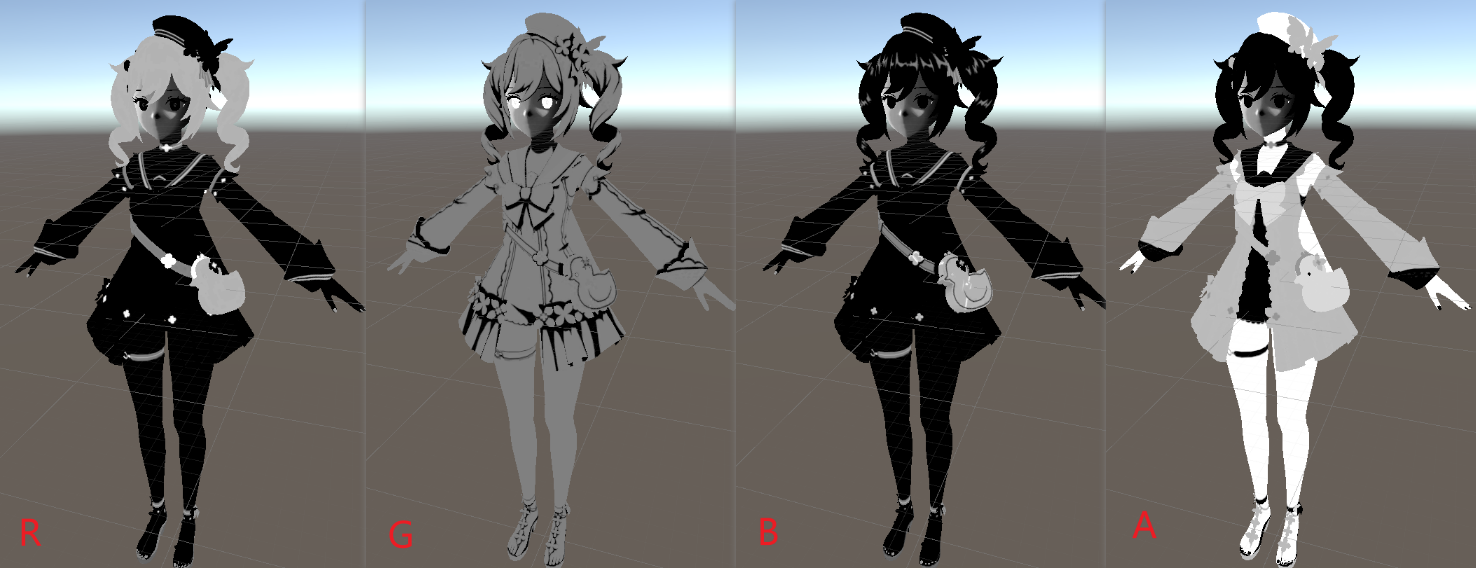
R:对高光区域进行分组,区分单独Blinn-Phong高光的区域和Matcap+Blinn-phong高光的区域
G:存储阴影权重,在这里实际上就是AO
B:存储Blinn-Phong高光的强度,同时作为高光区域遮罩
A:对材质进行分组,用于读取不同的Ramp图
Ramp图
存储阴影以及亮暗过渡区域的Color Tint颜色
SDF面部阴影贴图
基于光照的角度存储阴影阈值信息
MatCap贴图
存储模拟金属光泽的反射强度信息
Diffuse贴图
存储模型漫反射颜色
Outline贴图
自制的存储切线空间下顶点平滑法线信息的贴图
RG通道:存储切线空间下
B通道:控制描边区域
A通道:控制Ramp图影响范围(因为游戏中脖子部位和脸的下方是不受到Ramp图影响的,所以利用这个通道标记了一下不绘制ramp的区域。不过代价是在这个Pass中多读了一张贴图,后续再进行优化)
Diffuse漫反射
Diffuse的表现效果我大概迭代了三个版本,总算是调整到了一个看上去感觉还不错的效果,不过距离游戏里的表现还相去甚远,后续再继续研究分析,做进一步的效果提升。
几次迭代下来,我认为在Shading阶段的Diffuse关键在于,合适且美观地结合Ramp图做出出色的阴影表现,所以以下我重点说一说我对Ramp效果的处理方式。
Barbara身体的Ramp
身体的Ramp分为三层,上下两个部分分别是白天的ramp和夜间的ramp
Body的Lightmap A通道同样是有三层,分为衣领、皮肤和衣服三个部分(以及还有一个胸口的蝴蝶结)
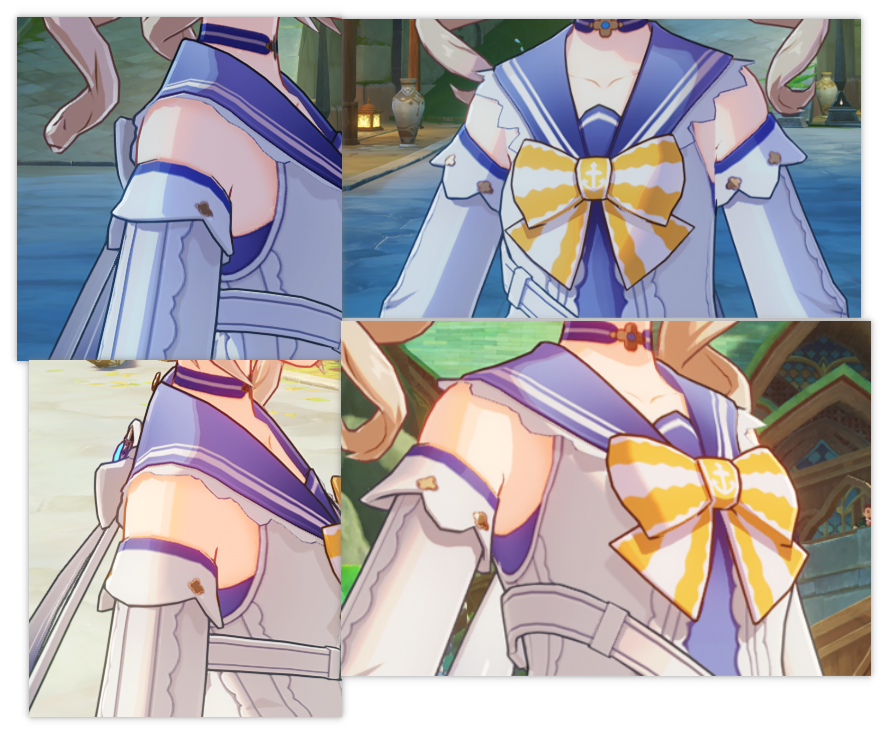
再来看看游戏中实际的效果表现:
可以根据颜色的偏移得出以下判断:(其中的数字为lightmap.a中对应区域大致的灰度数值)
Barbara头发的Ramp
头发的Ramp分为两层,上下两个部分分别是白天的ramp和夜间的ramp
再来看看游戏中实际的效果表现:
轻易能看出来,Day/Night的Ramp第一行是头发的(对应Lightmap A通道的数值是0),Ramp第二行是帽子和丝带的(对应Lightmap A通道的数值是1)
RampUV.Y
综合一下可以发现,ramp第一行对应lightmap.a<0的区域,ramp第二行对应lightmap.a>0.7的区域,ramp第三行对应lightmap.a>0.52的区域(我开始思考是不是我的贴图错了,因为同时包含两个白天和夜晚的ramp,这也不能直接利用贴图的repeat来处理0跑到最上面的问题啊QAQ)
这一次,在百思不得其解之后,我选择了使用if来暴力解决(对不起!但是为了效果目前只能先这样了,一定还有我没摸索到的更深层次的原因,我会继续探究的!)
所以对于Ramp图UV的V轴处理就如下所示:
//处理RampUV的V轴 if (layers <= 0.01) { RampTexUV.y = 0.5 * _RampDailyMode + 9 * RampTexelY; } else if (layers >= 0.6) { RampTexUV.y = 0.5 * _RampDailyMode + 7 * RampTexelY; } else { RampTexUV.y = 0.5 * _RampDailyMode + 5 * RampTexelY; }
因为这次重点针对芭芭拉的ramp图效果进行迭代和优化,所以没有考虑其他角色的通用性,后续整理代码的时候会加上其他角色更多Ramp区域的读取方式。
RampUV.X – Ramp表现的细节分析
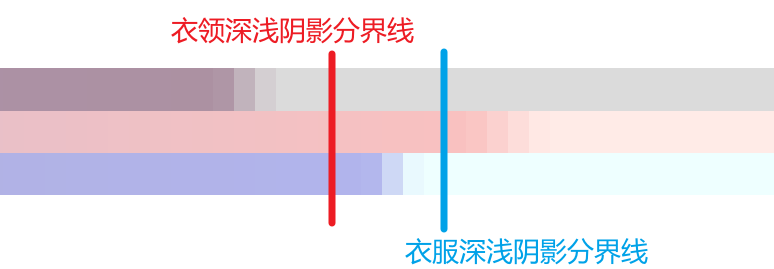
迭代着迭代着,再加上一次次地原神启动,我发现了两个问题:为什么Ramp图中过渡的区域是不同的呢?为什么不是在同一个地方进行的明暗交界?
下面这张图要明显一点,在同样的光照计算中,并且仅仅是透视无法得到同样效果的前提下,可以看出来衣领的浅阴影-亮面分界 与衣服的浅阴影-深阴影分界 是接近的
再来看之前的Ramp图,在同样的光照信息采样的前提下,不同部分的ramp颜色变化区域是不同的。
所以,对于光从0到1的变化过程中,衣领的阴影变化会先到来,然后是衣服的阴影变化,最后是皮肤、蝴蝶结的阴影变化
不过再来看看阴影结束(也就是完全亮部的分界线),不同部分几乎是相同的
可以分析出来各个Ramp部分截取的都是相同的一段X区间上的Ramp信息,是Ramp颜色过渡部位的不同导致的阴影偏移。不过到现在我还是无法理解为什么要这么处理,等后续再去研究研究色彩和阴影的美术原理,或许能找到一些答案。
继续分析下去,再看一下游戏中的整体的阴影表现,是接近于对半平分的阴影
我总结出的个人理解是:阴影可以分为三层,浅阴影、过渡层、深阴影
放大可以发现,浅阴影层和亮部的区分明显,浅阴影层和过渡层之间有一点点的平滑过渡,过渡层和深阴影层之间有平滑的过度关系,有一种颜色向深阴影层扩散的感觉。
如果直接用halflamber加step的柔化去采样,即使加上Bloom后细节效果也不够好:
肉眼可见有几个问题:
浅阴影层和过渡层之间的过渡很生硬,并且有“一条一条”的感觉
过渡层到深阴影层之间,及时加了适度的Bloom也没有那种“扩散过去”的感觉
总感觉深阴影层的颜色没有那么偏紫
所以感觉下来,好像深层阴影的颜色像亮部一样,并不是由ramp图控制的,如果这个假设成立,那可以有以下的解决方案:
深阴影层颜色偏移由另外的参数控制,其与过渡层之间有Lerp的平滑过渡处理,并且Lerp范围比较大
过渡层只是提取了光照信息的一小个区间,读取了一整张的ramp贴图
原本浅阴影和亮部之间处理二分的思路是:RampTexUV.x = min(0.99, smoothstep(0.0, 0.5 + _IntermediateToShallowShadowOffset, halfLambert));也就是截取了halfLambert数值0~0.5+_IntermediateToShallowShadowOffset 之间数值映射到0~1之间,作为ramp的u轴去采样ramp图的横向信息。
所以直接加入一个参数来对smoothstep的左边界进行控制即可:RampTexUV.x = min(0.99, smoothstep(0.5 - _IntermediateToDarkShadowOffset, 0.5 + _IntermediateToShallowShadowOffset, halfLambert));同时,其中的SmoothStep处理的区间,则被用作平滑处理的遮罩rampSmoothMask,用于后续对DarkShadow区域和Intermediate区域进行融合处理,模拟“扩散过去”的感觉
最终得到的效果:
总的用于获取RampUV信息的函数:
//计算一个rampSmoothMask用于平滑DarkShadow与IntermediateShadow之间的分界 float2 GetRampUV(float halfLambert, float layers, out float rampSmoothMask) { float2 RampTexUV; float RampTexelY = 0.05; //处理RampUV的V轴 if (layers <= 0.01) { RampTexUV.y = 0.5 * _RampDailyMode + 9 * RampTexelY; } else if (layers >= 0.6) { RampTexUV.y = 0.5 * _RampDailyMode + 7 * RampTexelY; } else { RampTexUV.y = 0.5 * _RampDailyMode + 5 * RampTexelY; } //处理RampUV的U轴 rampSmoothMask = smoothstep(0.5 - _IntermediateToDarkShadowOffset, 0.5 + _IntermediateToShallowShadowOffset, halfLambert); RampTexUV.x = min(0.94, rampSmoothMask); return RampTexUV; }
最终对diffuse color的计算:
//Diffuse: float lightMapAOMask = 1 - smoothstep(saturate(lightMapTexCol.g), 0.06, 0.6); float rampSmoothMask; float2 RampTexUV = GetRampUV(halfLambert, lightMapTexCol.a, rampSmoothMask); half4 rampCol = SAMPLE_TEXTURE2D(_RampTex, sampler_RampTex, RampTexUV); //通过rampSmoothMask平滑DarkShadow与IntermediateShadow之间的分界 half4 shadowColorTint = ifRamp * lerp(_DarkShadowColorTint, rampCol, rampSmoothMask) + (1-ifRamp)*_DarkShadowColorTint*1.5; //通过控制shadowMask来控制ShallowShadow的宽度 float shadowMask = step(_ShallowShadowWidth + 0.5, halfLambert * lightMapAOMask); //与漫反射贴图融合得到最终的漫反射颜色 half4 diffuseCol = diffuseTexCol * (shadowMask * _BrightAreaColorTint + (1.0 - shadowMask) * shadowColorTint);
Specular高光反射
关于Specular其实没有太多自己的创新,就是Blinn-Phong高光与MatCap模拟金属高光的结合。网上也能找到很多大佬的处理思路,等之后有更新的高光处理思路,再多做记录
其中使用的是lightmap的R通道对高光类型进行区分
<10的部分是没有高光的部分
10~100的部分只有Blinn-Phong高光
>100的部分有Blinn-Phong高光和采样MatCap制作的金属镜面高光
代码如下:
//Specular: //通过lightmap的R通道来对高光进行分层 const float specularLayer = lightMapTexCol.r * 255.0; //lightmap的b通道则是控制blinn-phong高光的强度,并同时作为Specular的遮罩 const float blinnPhongSpecIntensity = lightMapTexCol.b; //先计算通用的Blinn-Phong高光 float blinnPhongSpec = step(0.75, max(0.0, pow(ndoth, _SpecularExp))) * blinnPhongSpecIntensity; //specularLayer>100的部分有Blinn-Phong高光和采样MatCap制作的裁边视角光,所以对此部分进行MatCap的计算 float matcapSpec = 0.0; if (specularLayer > 100) { //MatCap需要基于视角空间的法线去读取,并且注意读取发现后需要映射到0-1区间 matcapSpec = saturate(SAMPLE_TEXTURE2D(_MetalTex, sampler_MetalTex, mul((float3x3)UNITY_MATRIX_V, i.normalWS).xy * 0.5 + 0.5).r); } //处理头发天使轮的遮罩 matcapSpec *= step(0.25, blinnPhongSpecIntensity); half4 specularCol = (matcapSpec + blinnPhongSpec) * diffuseTexCol;
RimLight边缘光
边缘光是在屏幕空间下计算的等距边缘光,制作思路是,开启Depth Texture的Prepass,在Shader中拿到深度图。让模型在齐次裁剪空间下进行一定程度地法线外扩,通过比较外扩前和外扩后模型读取到的深度,如果深度插值达到阈值则判定为边缘光区域,对边缘光区域进行提亮处理。
【posCS的计算】
值得提一下的是,需要获得posCS(齐次裁剪空间的坐标),但是这个posCS不能是直接由vertx shader中计算好的用于输出给SV_Target进行屏幕映射的vertexOutput.posCS(fragment中的i.posCS),因为在一定的深度范围中才会有线性的变化,并且在一个区间中会有明显的跳变。目前我还不知道原因是什么。
但是如果换作在fragment shader中利用i.posWS计算出来的就可以平滑处理
做一下对比探究一下:
这是vertex shader中计算posCS的方式:
float4 TransformObjectToHClip(float3 positionOS) { // More efficient than computing M*VP matrix product return mul(GetWorldToHClipMatrix(), mul(GetObjectToWorldMatrix(), float4(positionOS, 1.0))); }
这是fragment shader中计算posCS的方式:
float3 TransformObjectToWorld(float3 positionOS) { #if defined(SHADER_STAGE_RAY_TRACING) return mul(ObjectToWorld3x4(), float4(positionOS, 1.0)).xyz; #else return mul(GetObjectToWorldMatrix(), float4(positionOS, 1.0)).xyz; #endif } // Tranforms position from world space to homogenous space float4 TransformWorldToHClip(float3 positionWS) { return mul(GetWorldToHClipMatrix(), float4(positionWS, 1.0)); }
实际上两个方法的计算过程是一致的,只不过在vertex中计算出来的posCS直接插值传递给fragment,而在fragment中利用插值后的WS计算CS是逐fragment去计算的。但是矩阵变换是线性变换的,这些也是在线性空间完成的,按理说插值应该不会影响效果才对。那么感觉就是插值寄存器的问题
【深度的线性转化】
我们通过深度图拿到的深度信息实际上是经过透视变换之后的深度,不是线性空间的(这样可以用更高精度存近处的深度,更低精度存远处的深度),但是在进行对比时,我们需要的是线性空间的深度值来作差,所以我们需要对深度进行转化,Unity提供了Linear01Depth和LinearEyeDepth两个函数来进行转换。
Linear01Depth和LinearEyeDepth最终得到的深度值的区别在于是否压缩到0-1空间中,压缩方法也就是除以far
// Z buffer to linear 0..1 depth (0 at camera position, 1 at far plane). // Does NOT work with orthographic projections. // Does NOT correctly handle oblique view frustums. // zBufferParam = { (f-n)/n, 1, (f-n)/n*f, 1/f } float Linear01Depth(float depth, float4 zBufferParam) { return 1.0 / (zBufferParam.x * depth + zBufferParam.y); } // Z buffer to linear depth. // Does NOT correctly handle oblique view frustums. // Does NOT work with orthographic projection. // zBufferParam = { (f-n)/n, 1, (f-n)/n*f, 1/f } float LinearEyeDepth(float depth, float4 zBufferParam) { return 1.0 / (zBufferParam.z * depth + zBufferParam.w); }
而_ProjectionParams.z的值是far
所以Linear01Depth(offsetDepth, _ZBufferParams)*_ProjectionParams.z和LinearEyeDepth(0ffsetDepth, _ZBufferParams)是等效的
【最后的代码】
计算边缘光的代码如下所示:
//Rim Light float4 posCS = TransformWorldToHClip(i.posWS); //获取原本的深度: float4 orgPosCS = float4(posCS.xy, 0.0, posCS.w); //很有意思的一点是,这里的orgPosCS需要是由世界空间posWS经过shader内部自己计算出来的posCS,如果用 float4 orgScreenPos = ComputeScreenPos(orgPosCS); //计算出齐次空间下的ScreenPos,注意此处是没有进行透视除法的 float2 orgVPCoord = orgScreenPos.xy / orgScreenPos.w; //进行透视除法,获取屏幕空间坐标 float orgDepth = SampleSceneDepth(orgVPCoord); //读取没有偏移时的深度信息,使用SampleSceneDepth函数需要引入DeclareDepthTexture.hlsl float orgLinearDepth = LinearEyeDepth(orgDepth, _ZBufferParams); //将深度信息转换到视角空间下 //获取偏移之后的深度: float3 normalCS = TransformWorldToHClipDir(i.normalWS, true); //计算出齐次裁剪空间下的法线方向 float4 rimOffsetPosCS = float4(normalCS.xy * _RimLightWidth + posCS.xy, 0.0, posCS.w); //计算出齐次裁剪空间下的偏移位置 float4 rimOffsetScreenPos = ComputeScreenPos(rimOffsetPosCS); float2 offsetVPCoord = rimOffsetScreenPos.xy / rimOffsetScreenPos.w; float offsetDepth = SampleSceneDepth(offsetVPCoord); //得到偏移后的深度信息 float offsetLinearDepth = LinearEyeDepth(offsetDepth, _ZBufferParams); //将深度信息转换到视角空间下 //进行比较: float depthDiff = offsetLinearDepth - orgLinearDepth; //计算出偏移后和偏移前的深度差(Unity中,离摄像机越近,深度值越接近1) float rimFactor = 1 - smoothstep(60.0, 100.0, orgLinearDepth); //rim factor由距离控制是否需要产生边缘光,并平滑使边缘光消失 float rimEdgeMask = smoothstep(10.0, 20.0, depthDiff) * rimFactor; //得到边缘光遮罩 return diffuseCol * rimEdgeMask * 1.5 + diffuseCol * (1 - rimEdgeMask);
SDF制作面部阴影
【原理浅析】
为了使面部阴影效果更好(一是二分,二是鼻翼侧边的高光),开发者们根据光照的方向,制作了几张面部的lightmap,作为特定角度下面部的阴影表现。然而,直接把这几张贴图合并在一起使用的话,面部的阴影只能是跳变的效果,也就是阴影表现只有在特定角度才会切换,在某个角度区间内阴影表现是固定的。所以引入了SDF,有向距离场的技术:通过“距离场”,把每一张lightmap从单纯的0或1的区分,处理为了距离阴影分界线从0到1之间的数值,可以理解为特定角度下不同区域的阴影权重。通过“有向”来界定了该区域是在阴影内还是阴影外。最终合并后就得到如下的结果
【实际使用】
模型的头骨是经过旋转的,直接使用lightDir计算会有问题,不过我因为直接是用的mmd的模型,好像因此差距不是很大。所以我的处理是在用原始的light方向判断完左右信息之后,再利用旋转矩阵对光源的方向进行一定程度的旋转,通过旋转光源来进一步优化一下阴影的表现,也便于在视频中根据内容实时调整阴影。
//获取世界空间下的光照信息,并在世界空间下计算光源与角色forward向量之间的夹角信息,并判断光源此时是在角色的左侧还是右侧 half2 lightDir = mainLight.direction.xz; float rdotl = dot(rightDirWS.xz, lightDir); //默认的贴图光是从角色的左侧照射向角色的,所以当点乘小于零的时候用默认uv,当点乘大于0的时候左右翻转uv //温馨提示:左右翻转uv本来应该是1-uv.x,但是如果把texture的Wrap Mode改为Repeat的话就可以用-uv.x来表示了 float2 shadowmapUV = rdotl < 0 ? i.uv : float2(-i.uv.x, i.uv.y); float faceSDF = SAMPLE_TEXTURE2D(_FaceSDFTex, sampler_FaceSDFTex, shadowmapUV).x; //利用SDF计算光照信息时需要对光方向进行偏移 float sinx = sin(_FaceShadowOffset); float cosx = cos(_FaceShadowOffset); float2x2 rotationOffset1 = float2x2(cosx, sinx, -sinx, cosx); //顺时针偏移 float2x2 rotationOffset2 = float2x2(cosx, -sinx, sinx, cosx); //逆时针偏移 lightDir = lerp(mul(rotationOffset1, lightDir), mul(rotationOffset2, lightDir), step(0, rdotl)); float fdotl = dot(forwardDirWS.xz, lightDir); float lightMask = step(0.5 * fdotl, faceSDF); //需要去截取出每一个角度的SDF信息, //SDF信息的变化(即不同距离场贴图的区分)是按照光源与角色左右方向上的轴的夹角区分的 //乘0.5是因为身体和头发使用的是半兰伯特光照模型,为了保持阴影分界线尽可能统一而在fdotl后乘0.5 //原理同faceSDF > 0.5 * fdotl,是同一个算法 //读取通用贴图 half4 diffuseTexCol = SAMPLE_TEXTURE2D(_DiffuseTex, sampler_DiffuseTex, i.uv); half4 diffuseCol = lerp(diffuseTexCol * _ShadowAreaColorTint, diffuseTexCol * _BrightAreaColorTint, lightMask);
BackFace描边
平滑法线处理
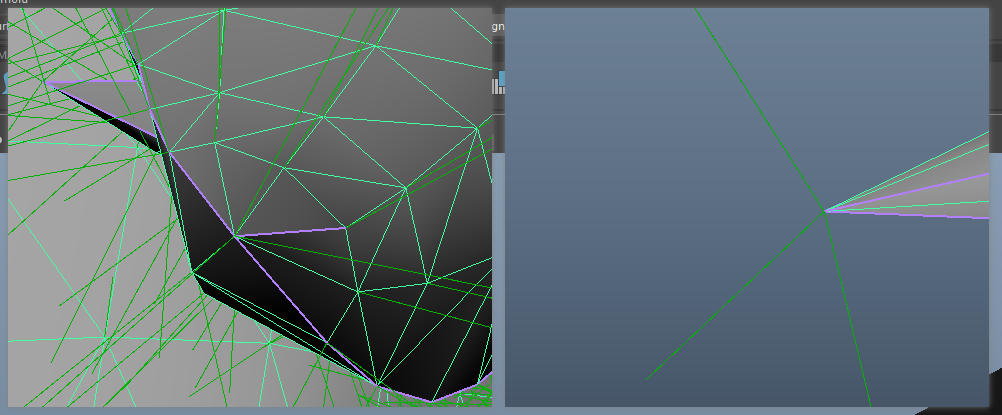
因为直接使用模型的法线进行外扩的话,对于硬边上的顶点,一个位置实际上有多个顶点,每个顶点有其各自的法线朝向。当进行外扩时,就会出现描边断裂的效果。
硬边一个顶点有多条法线,导入引擎后实际上就是硬边把一个顶点分成了多个顶点,数量则等于硬边所区分的面的数量(这也是为什么引擎中看模型数据顶点数会大于DCC建模软件中所见的顶点数):
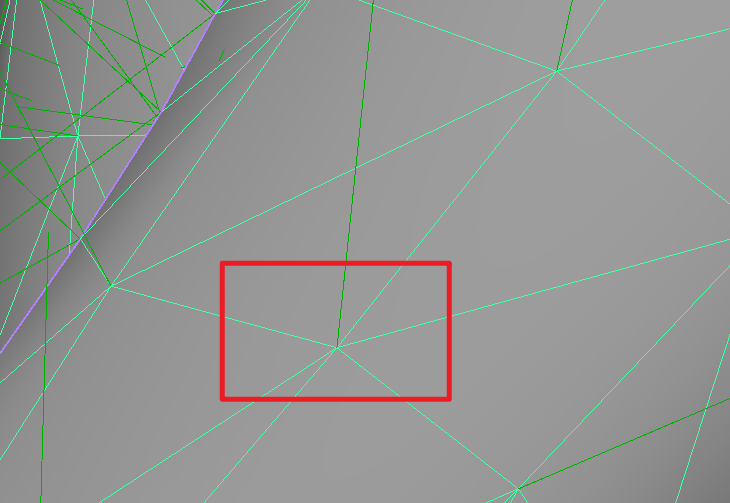
而软边只有一条法线:
关于工具的详细内容我放在另一个文章中写
最后计算出平滑法线后我将这些信息存到了一张贴图里面,也就是一开始说得那几张outline贴图
描边颜色和区域控制
描边的颜色我用顶点色来进行控制,描边的区域则是在平滑法线贴图的A通道进行控制
最终效果
Unity中的描边内容如下:
OutlineVaryings NPROutlineVertex(OutlineAttributes vertexInput) { OutlineVaryings vertexOutput; float4 pos = TransformObjectToHClip(vertexInput.posOS.xyz); float2 uv = TRANSFORM_TEX(vertexInput.uv, _SmoothNormalTex).xy; float3 smoothNormalTexCOl = SAMPLE_TEXTURE2D_LOD(_SmoothNormalTex, sampler_SmoothNormalTex, uv, 0).xyz; //构建TBN矩阵,并将平滑法线信息转换到世界空间下 float3 normalWS = TransformObjectToWorldNormal(vertexInput.nomralOS); float3 tangentWS = TransformObjectToWorldDir(vertexInput.tangentOS.xyz); float3 bitangentWS = normalize(vertexInput.tangentOS.w * abs(cross(normalWS, tangentWS))); float3x3 TBN = float3x3(tangentWS, bitangentWS, normalWS); float3 smoothNormalTS = float3(smoothNormalTexCOl.r, smoothNormalTexCOl.g, sqrt(1 - (dot(smoothNormalTexCOl.r, smoothNormalTexCOl.g)))); float3 smoothNormalWS = mul(smoothNormalTS, TBN); float3 smoothNormalCS = TransformWorldToHClipDir(smoothNormalWS, true); //VertexColor的Blue通道用于控制描边区域 half toDrawOutline = saturate(1 - step(0.1, smoothNormalTexCOl.b)); //计算出屏幕的高/宽的值,用于平衡水平描边和竖直描边因屏幕映射而导致的拉伸 float4 screenParam = GetScaledScreenParams(); float HdW = screenParam.y / screenParam.x; float2 offset = _OutlineWidth * clamp(0.1, 0.5, pos.w) * 0.01 * float2( smoothNormalCS.x * HdW, smoothNormalCS.y); pos.xy += offset * toDrawOutline; vertexOutput.posCS = pos; vertexOutput.outlineColor = vertexInput.vertexCol; return vertexOutput; } half4 NPROutlineFragment(OutlineVaryings i) : SV_Target { return i.outlineColor; }
后处理(DOF + Bloom)
这次后处理没有太考虑性能方面的问题,过程很暴力,后续进行优化,核心就是遮罩、模糊和混合。主要的难点在于URP的后处理比Built-in管线写起来要复杂一些。具体的制作内容我同样会再写其他文章来分享,这里只是做一个总述。
DOF景深效果
我对DOF的处理方法是,先利用深度信息去计算出模糊区域的遮罩,通过遮罩提取出模糊区域,进行高斯模糊处理。然后再基于遮罩,对原图和计算后的模糊图像进行混合(如果不利用遮罩的话,背景区域的模糊会扩散进清晰区域,得到的效果就没那么好)
然后混合后就是如下结果:
Bloom
Bloom参考了COD在SIGGRAPH 2014 Advances in Real-Time Rendering in Games 课程中分享的Bloom处理思路。主要借鉴了升采样和降采样的步骤,因为一开始做Bloom都是直接模糊然后混合,得到的效果不太好,所以用升降采样的思路进行处理。
注:Bloom的输入源是DOF的输出,所以以下是在DOF景深计算后的基础上得到的内容
然后进行混合:
Timeline控制自定义后处理中的参数
十分感谢这位大佬的分享:https://www.bilibili.com/read/cv4828303/
基本就是照着这位大佬的流程制作的,后续我深入研究一下API再整理一遍思路
借物表